publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
-
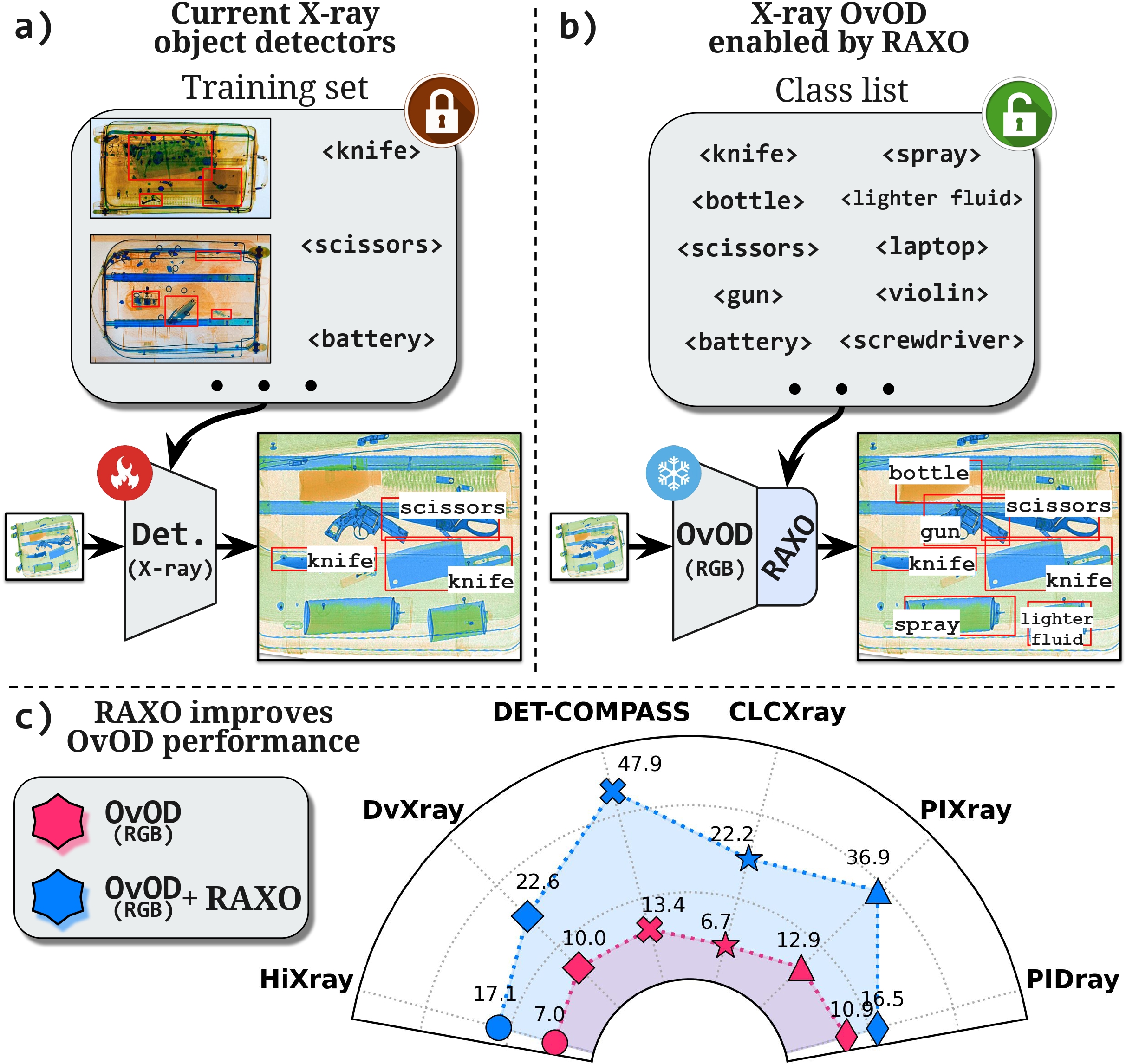 Superpowering Open-Vocabulary Object Detectors for X-ray VisionPablo Garcia-Fernandez, Lorenzo Vaquero, Mingxuan Liu, and 5 more authorsIn IEEE International Conference on Computer Vision (ICCV), 2025
Superpowering Open-Vocabulary Object Detectors for X-ray VisionPablo Garcia-Fernandez, Lorenzo Vaquero, Mingxuan Liu, and 5 more authorsIn IEEE International Conference on Computer Vision (ICCV), 2025Open-vocabulary object detection (OvOD) is set to revolutionize security screening by enabling systems to recog nize any item in X-ray scans. However, developing effective OvOD models for X-ray imaging presents unique challenges due to data scarcity and the modality gap that prevents direct adoption of RGB-based solutions. To overcome these limitations, we propose RAXO, a training-free framework that repurposes off-the-shelf RGB OvOD detectors for robust X-ray detection. RAXO builds high-quality X-ray class descriptors using a dual-source retrieval strategy. It gathers relevant RGB images from the web and enriches them via a novel X-ray material transfer mechanism, eliminating the need for labeled databases. These visual descriptors replace text-based classification in OvOD, leveraging intra-modal feature distances for robust detection. Extensive experiments demonstrate that RAXO consistently improves OvOD performance, providing an average mAP increase of up to 17.0 points over base detectors. To further support research in this emerging field, we also introduce DET-COMPASS, a new benchmark featuring bounding box annotations for over 300 object categories, enabling large-scale evaluation of OvOD in X-ray.
@inproceedings{garcia2025superpowering, title = {Superpowering Open-Vocabulary Object Detectors for X-ray Vision}, author = {Garcia-Fernandez, Pablo and Vaquero, Lorenzo and Liu, Mingxuan and Xue, Feng and Cores, Daniel and Sebe, Nicu and Mucientes, Manuel and Ricci, Elisa}, booktitle = {IEEE International Conference on Computer Vision (ICCV)}, year = {2025}, } -
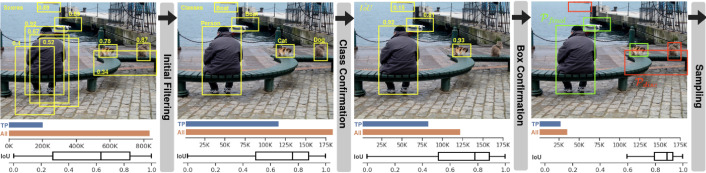 Enhancing few-shot object detection through pseudo-label miningPablo Garcia-Fernandez, Daniel Cores, and Manuel MucientesImage and Vision Computing, 2025
Enhancing few-shot object detection through pseudo-label miningPablo Garcia-Fernandez, Daniel Cores, and Manuel MucientesImage and Vision Computing, 2025Few-shot object detection involves adapting an existing detector to a set of unseen categories with few annotated examples. This data limitation makes these methods to underperform those trained on large labeled datasets. In many scenarios, there is a high amount of unlabeled data that is never exploited. Thus, we propose to exPAND the initial novel set by mining pseudo-labels. From a raw set of detections, xPAND obtains reliable pseudo-labels suitable for training any detector. To this end, we propose two new modules: Class and Box confirmation. Class Confirmation aims to remove misclassified pseudo-labels by comparing candidates with expected class prototypes. Box Confirmation estimates IoU to discard inadequately framed objects. Experimental results demonstrate that xPAND enhances the performance of multiple detectors up to +5.9 nAP and +16.4 nAP50 points for MS-COCO and PASCAL VOC, respectively, establishing a new state of the art.
@article{garcia2025enhancing, title = {Enhancing few-shot object detection through pseudo-label mining}, author = {Garcia-Fernandez, Pablo and Cores, Daniel and Mucientes, Manuel}, journal = {Image and Vision Computing}, volume = {154}, pages = {105379}, year = {2025}, publisher = {Elsevier}, } -
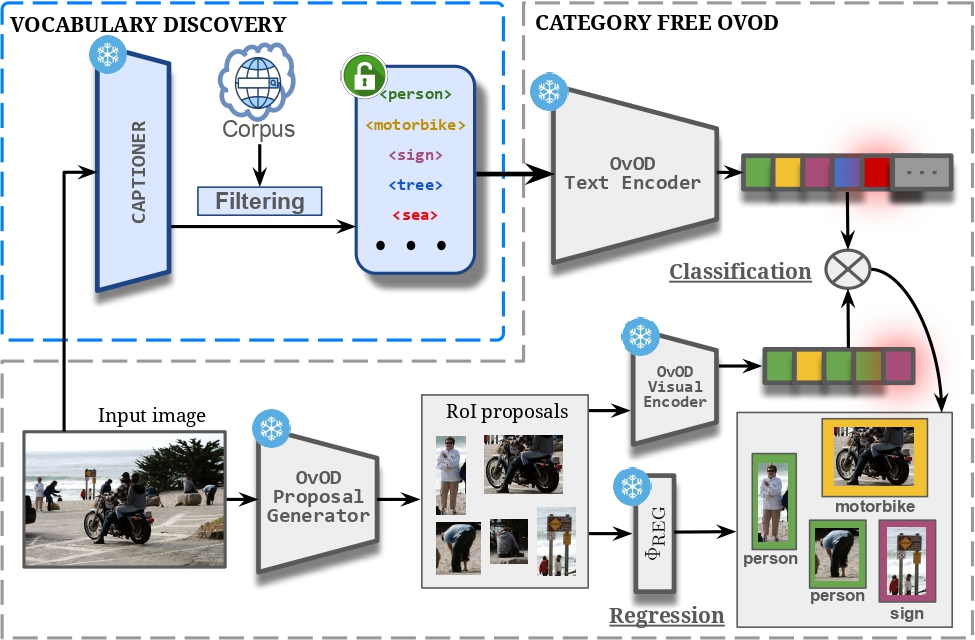 Exploring Open-Vocabulary Models for Category-Free DetectionPablo Garcia-Fernandez, Daniel Cores, and Manuel MucientesIn International Conference on Computer Analysis of Images and Patterns (CAIP), 2025
Exploring Open-Vocabulary Models for Category-Free DetectionPablo Garcia-Fernandez, Daniel Cores, and Manuel MucientesIn International Conference on Computer Analysis of Images and Patterns (CAIP), 2025Object detection models typically rely on a predefined set of categories, limiting their applicability in real-world scenarios where object classes may be unknown. In this paper, we propose a novel, training-free framework that enables off-the-shelf open-vocabulary ob- ject detectors (OvOD) to perform category-free detection —localizing and classifying objects without any prior category knowledge. Our ap- proach leverages image captioning to dynamically generate descriptive terms directly from the image content, followed by a WordNet-based fil- tering process to extract semantically meaningful category names. These discovered categories are then embedded and matched with visual region features using a frozen OvOD model to perform detection. We evaluate our method on the COCO dataset in a fully zero-shot setting and demon- strate that it significantly outperforms strong multimodal large language model baselines, achieving an improvement of over 30 AP points. This highlights our method as a promising direction for more adaptive solu- tions to real-world detection challenges.
@inproceedings{garcia2025exploring, title = {Exploring Open-Vocabulary Models for Category-Free Detection}, author = {Garcia-Fernandez, Pablo and Cores, Daniel and Mucientes, Manuel}, booktitle = {International Conference on Computer Analysis of Images and Patterns (CAIP)}, year = {2025}, }